wxai Implementation
Preprocess Source Documents
Preprocess MSR docuemnt and attach the relevant metadata
To retrieve the relevant metadata from the MSR document, we need to first identify where the Minimum Security Requirements section is along with what the subsections are to figure out when the section begins and end.
Now let's create a section_extraction function that takes in the name of the pdf file.
In the function, there are four main parts. The first part is to utilize the PdfReader from the PyPDF2 library to read and extract the content from the MSR pdf.
Then, loop through the pdf and remove any headers, footers, or new lines from the extracted content.
Afterwards, create a nested-loop to extract the file name, header, summary, subheading, and the subheading's content and place it into a dictionary format.
Here is an example of the dictionary format:
value == where the extracted content belong
dictionary = {File Name: "value", Header: "value", Summary: "value", Subheading: "value", Content: "value"}, {...}, ...
This is where you can use python's find() function to find the content to match the key of the dictionary. Lastly, place the finished dictionary into a final list and dump/write into a JSON file.
If you need support in constructing the function, you can find the pre-processing function here.
Vector Database - Chromadb
After we cut the MSR into chunks and stored it in json, we stored the chunks along with their associated metadata in a vector database. This allowed us to do semantic searches using the question text to find the most similar MSR context. The vector database that we used to store the msr context was created using chromadb. We used the default vector embedding and cosine similarity, although these could be tweaked for better results.
You can find the code where we ingested the documents into the vector database here. The content is just the text from that chunk of the MSR, and we stored information about headers, filename, and a summary in the metadata. We kept the formation of the ids the same, so that chromadb could recognize that we were not adding new chunks every time we reran a script that used the MSR vector database.
Create Reference Report
Extract SIG Question
To extract each of the questions from the blank SIG, we need to read the blank SIG as a pandas dataframe. the read_excel() function does this pretty well, but there were two important steps. First, because the blank SIG has multiple sheets, the object read out of the read_excel() function will be a dictionary of dataframes organized by sheet name. Second, the only one of these sheets we cared about is the "Content Library" sheet, because that sheet contains every question. Accordingly, our code to read the blank SIG and extract the questions was as follows:
def create_ref_sig(bs_df):
questions = bs_df["Content Library"].iloc[:, 2:4]
where bs_df is the object from the read_excel() function, and the only columns selected are the question and question number column.
Determine Reference Response
In order to create the Reference Report, the LLM needs to provide the best answer to each SIG question, answering to its best ability what the bank would want from their vendors. That is where the determine_response() function comes, as it takes in each SIG question then outputs a Yes/No Response and an Additional Context message to give more information, all in JSON format. To view the exact code, please check out this link. Otherwise, the prompt that was utilized is below:
prompt_input =
"""<|system|>
You are Granite Chat, an AI language model developed by the IBM DMF Alignment Team. You are a cautious assistant that carefully follows instructions. You are helpful and harmless and you follow ethical guidelines and promote positive behavior. You respond in a comprehensive manner unless instructed otherwise, providing explanations when needed while maintaining a neutral tone. You are capable of coding, writing, and roleplaying. You are cautious and refrain from generating real-time information, highly subjective or opinion-based topics. You are harmless and refrain from generating content involving any form of bias, violence, discrimination or inappropriate content. You always respond to greetings (for example, hi, hello, g'day, morning, afternoon, evening, night, what's up, nice to meet you, sup, etc) with "Hello! I am Granite Chat, created by the IBM DMF Alignment Team. How can I help you today?". Please do not say anything else and do not start a conversation.
<|user|>
I will give you a question from a Standardized Information Gathering (SIG) Questionnaire regarding security. Answer Yes or No. Use your best judgement as to what response the bank would want from their vendors.
Please answer only in the following manner and in json output:
{"Response": "Yes", "Additional Context":"<if any additional context>"}
{"Response": "No", "Additional Context":"<if any additional context>"}
<|assistant|>
Here are a few examples:
SIG Question #1: Does the password policy require password expiration within 90 days or less?
Answer: {"Response": "Yes", "Additional Context": "To ensure proper security protocol and risk mitigation, password policy should require password expiration within 90 days or less."}
SIG Question #2: Does the password policy require changing passwords when there is an indication of possible system or password compromise?
Answer: {"Response": "Yes", "Additional Context": "When any indication of system or password comprise occurs, passwords need to be changed."}
SIG Question #3: Does the password policy apply to all network devices including routers, switches, and firewalls?
Answer: {"Response": "Yes", "Additional Context": "Passwords for every system should adhere to password policy."}
SIG Question #4: Is there an administrative process to revoke authenticators if required?
Answer: {"Response": "Yes", "Additional Context": "The ability to revoke access to certain personnel should always be required."}
SIG Question #5: Is access to systems that store, or process scoped data limited?
Answer: {"Response": "Yes", "Additional Context": "Access should always be limited to systems that store confidential data."}
<|user|>
Please provide the answer to the following SIG Question in JSON:
"""+question+"""
Answer:
<|assistant|>
"""
Determine Relevant MSR Context
Determining the MSR context originally utilized just a vector database for semantic search, but we found that this created an unforseen issue. Although the MSR covers much of the same ground as the SIG questionaire, the venn diagram isn't a perfect circle, so to speak. When the SIG question does not have a truly relevant MSR context, we would still assign it the closest section of the MSR that the vector database could find, which then also found its way into the process for determining the reference response, producing results that sometimes seemed to align more with the MSR context than the question itself.
For example, the question from the section on Environmental, Social, and Governance (ESG) "Does the organization maintain processes to ensure there are no adverse impacts on biodiversity, including deforestation, ecosystem integrity, natural resource conservation, and land degradation?" would sometimes be given the reference response "No" because of the irrelevant MSR context provided.
To remedy this, we added an extra step after retrieving the three most similar chunk of the MSR that verifies if any of the MSR contexts is actually relevant or not, and if so which one is the most relevant. You can find this function along with the associated prompt we used here.
Determine Issue
Based on our experience with irrelevant MSR contexts causing issues further down the pipeline, we decided to implement a similar system for determining the most relevant issue from the catalog (if one exists). In this case, because we already know what domain the question is from the first letter of the question number we can filter out all of the issues not associated with that domain. The test_doc_needed() function checks if the issue references an external document, which we are excluding for this POC because we do not have any of those documents.
#Retrieve all the issues (that dont rely on external docs) corresponding to the letter/domain
def filter_issues(letter) :
num_rows, _ = df.shape
issues = []
for i in range(num_rows) :
if type(df.iloc[i, 1]) == str and df.iloc[i, 1][0].lower() == letter.lower() and not test_doc_needed(df, i):
qn = df.iloc[i, 0]
issue_desc = df.loc[i, "Issue Description"]
risk_statement = df.loc[i, "Risk Statement"]
issues.append({"Ques Num": qn, "Issue Description": issue_desc, "Risk Statement": risk_statement})
return issues
The next step is to do a relevancy check similar to the one done for the MSR context. You can find the code and prompt for that here.
Create Assessor Report
We created the assessor report according to this truth table, where we catagorize each vendor response as an issue, gap, or neither depending on their inputs in the response and additional information fields. We labelled the responses according to this truth table:
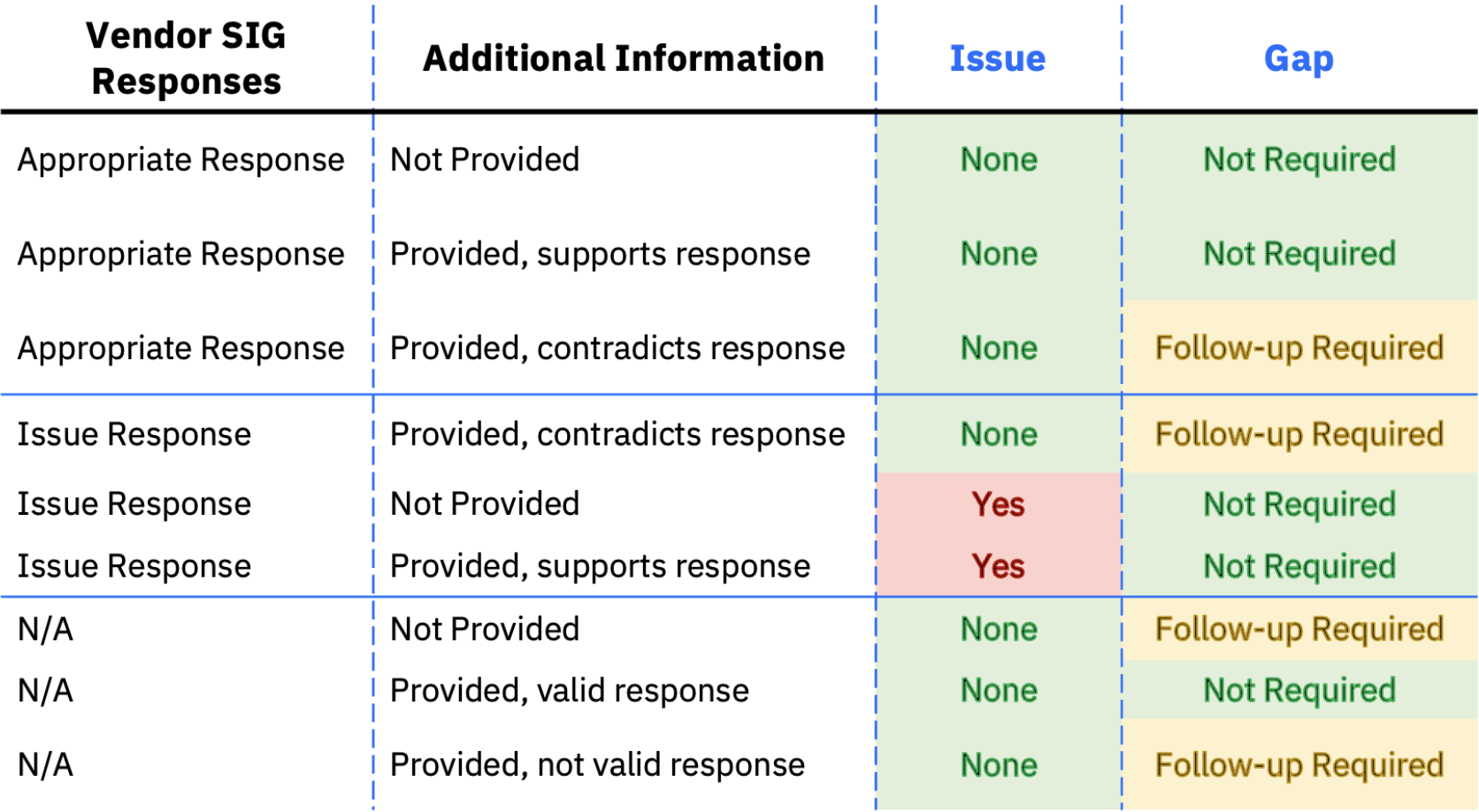
To determine if a response's additional information supports or contradicts their response, we used an LLM.
Classify Issue
If the response provided by the vendor is the inverse of the reference response, then its likely that there is an issue. Still, we needed to check for the rare case where the vendor provides additional information that would seemingly imply that their answer should have been the desired one. Alternatively, the vendor could also provide additional information that reasonably justifies their response. In either case, if the LLM determines that the additional information indicates that the vendor response is not a true issue, then it is reclassified as a gap.
In any other case, the original classification as an issue stands.
Classify Gap
Leverage an LLM to determine whether or not the "Additional Information" provided within the vendor SIG supports or contradicts the response the vendor provided in the SIG.
- If the "Additional Information" supports the vendor SIG response then classify the Gap as "No"
- If the "Additional Information" contradicts the vendor SIG response then classify the Gap as "Yes"
prompt =
(""" <|begin_of_text|><|start_header_id|>user<|end_header_id|> {INSTRUCTION}
You are provided with an input SIG question, vendor response in either "Yes" or "No", and a addtitional information provided by vendor to support their response. Based on your analysis, categorize the output into one of two categories:
1. "provided, contradicts response" in case additional information is provided but it does not support the response given by vendor.
2. "provided, supports response" in case additional information is provided and it supports the response given by vendor.
- Be very exact in generating output.
- Do not generate any reasoning in the output.\n\n""" +
"#### START OF QUESTION ####\n\n" +
"[input SIG Question: ]" + f"{input_ques}\n\n" +
"[vendor response: ]" + f"{resp}\n\n" +
"[additional info: ]" + f"{info}\n\n" +
"#### END OF QUESTION #### <|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n" +
"Output: ")
Provide MSR Context
Copy the relevant MSR context from the reference SIG for the respective SIG question.
Provide Recommendation
To successfully compare the vendor-given report to the Reference Report, there needs to be a function that takes in the SIG Question, its corresponding relevant MSR context, and its Additional Information (if given), to determine if the vendor-given report aligns with the Reference report. That is where the generate_recommendation() function came in as it takes in all 3 of those arguments to determine if the 2 reports are Relevant (Yes), Partially Relevant, or Not relevant (No), while additionally providing and explanation if necessary and follow-up questions to ask the vendor in the scenario where the reports are partially or not relevant. To check out our code, please feel free to view it at this link. In the meantime, view the prompt that was used here:
instruction =
"""You are a security analyst. I will give you three items, a Standardized Information Gathering (SIG) question, a Minimum Security Requirement (MSR) Reference text, and an Additional Information text. Determine if the Additional Information text answers the SIG question and/or if the Additional Information text supports the MSR Reference text. Output should be either Yes, No or Partially relevant. If applicable, please provide an explanation in detail and any follow-up questions that you'd like to ask the vendor.
For the explanation, explain in detail how you got to the conclusion of the status, be specific if the content was gathered from additional information to back up the selected status, and why you conclude with the selected status.
For the follow-up questions, you are expected to generate more than one follow-up question until you think it is enough to gather the answer we need to answer the SIG's question. Lastly, make sure the follow-up questions are in a numbered list.
Please answer in the following manner and in json output:
{"status": "Yes", "explanation and follow-up questions":"<if any explanation> <if any follow-up questions> "}
{"status": "Partially relevant", "explanation and follow-up questions":"<if any explanation> <if any follow-up questions> "}
{"status": "No", "explanation and follow-up questions":"<if any explanation> <if any follow-up questions> "}
Below is the status definition:
status: Yes, the Additional Information text addresses the SIG question and is in alignment with the MSR Requirement policies.
status: Partially relevant, either the Additional Information text addresses the SIG question or the Additional Information text is in alignment with the MSR requirement policies.
status: No, the Additional Information text does not addresses the SIG question and is not in alignment with the MSR Requirement policies.
Question:
{{Question}}
Minimum Security Requirement Text:
{{MSRContext}}
Vendor document:
{{AdditionalInfo}}
Result:"""
examples = """[
{
"input": "**DISCLAIMER: Follow examples for structure of what the output should look like**\n\nquestion = question content \n\nMSRcontext = MSR content \n\nAdditionalInfo = additional vendor info content ",
"output": "{\"status\": \"status answer\", \"explanation and follow-up questions\":\"Explanation content.\n\nFollow-up questions: \n1. Question 1 \n2. Question 2\n3. Question 3\"}"
}
]"""
input = """question = """+question+"""
"""+msr_context+"""
"""+additional_info+"""
"""
input_prefix = "Input:"
output_prefix = "Output:"
prompt_input = instruction + examples + input + input_prefix + output_prefix