Step Two: Environment Setup
Environment Setup & External Integrations
In this phase, we configure the environment by integrating essential external services:
- Data Sources & APIs:
Integration with Hugging Face for AI model or local model downloads, Gmail for email automation, and Yahoo Finance for real-time data. - Infrastructure:
Use of ElasticSearch for fast querying and IBM Code Engine for containerized PDF generation.
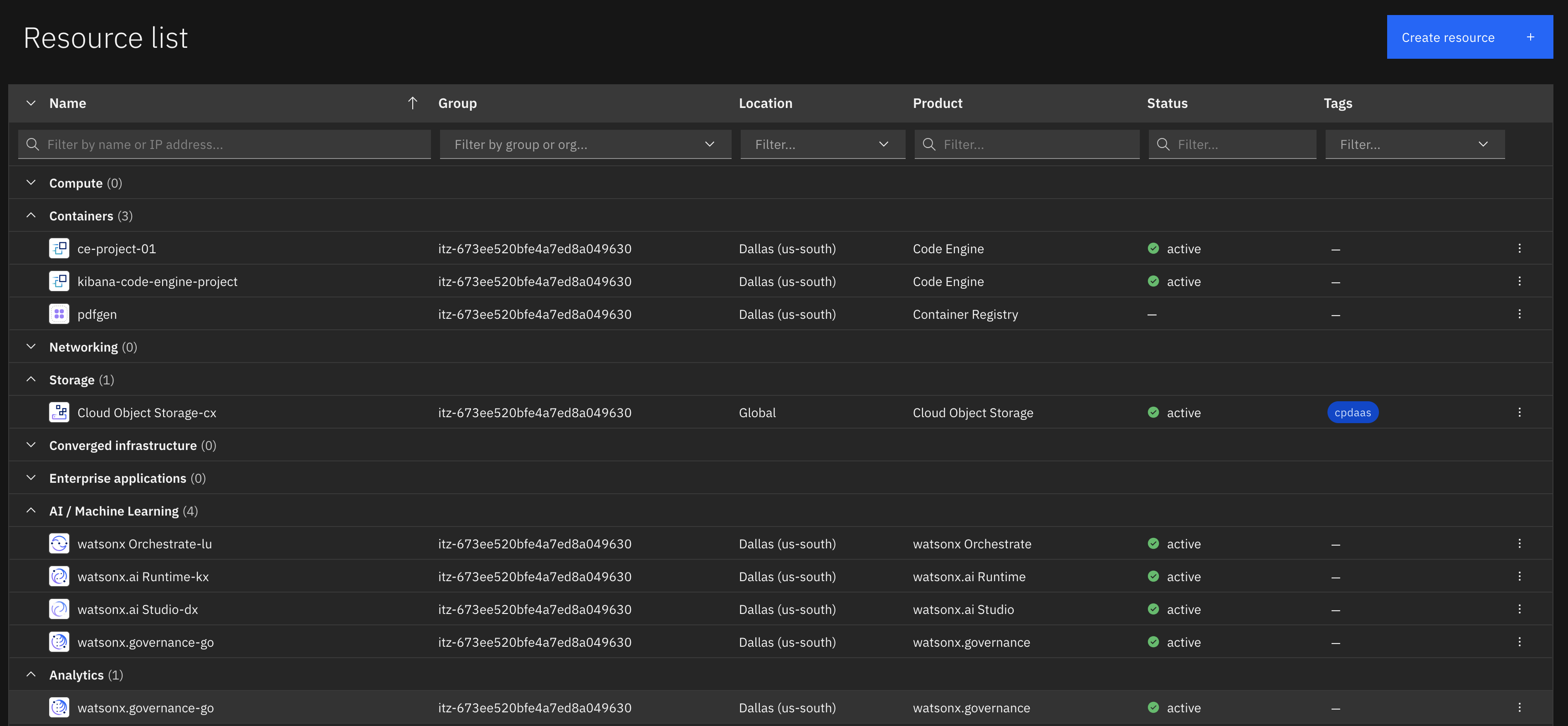
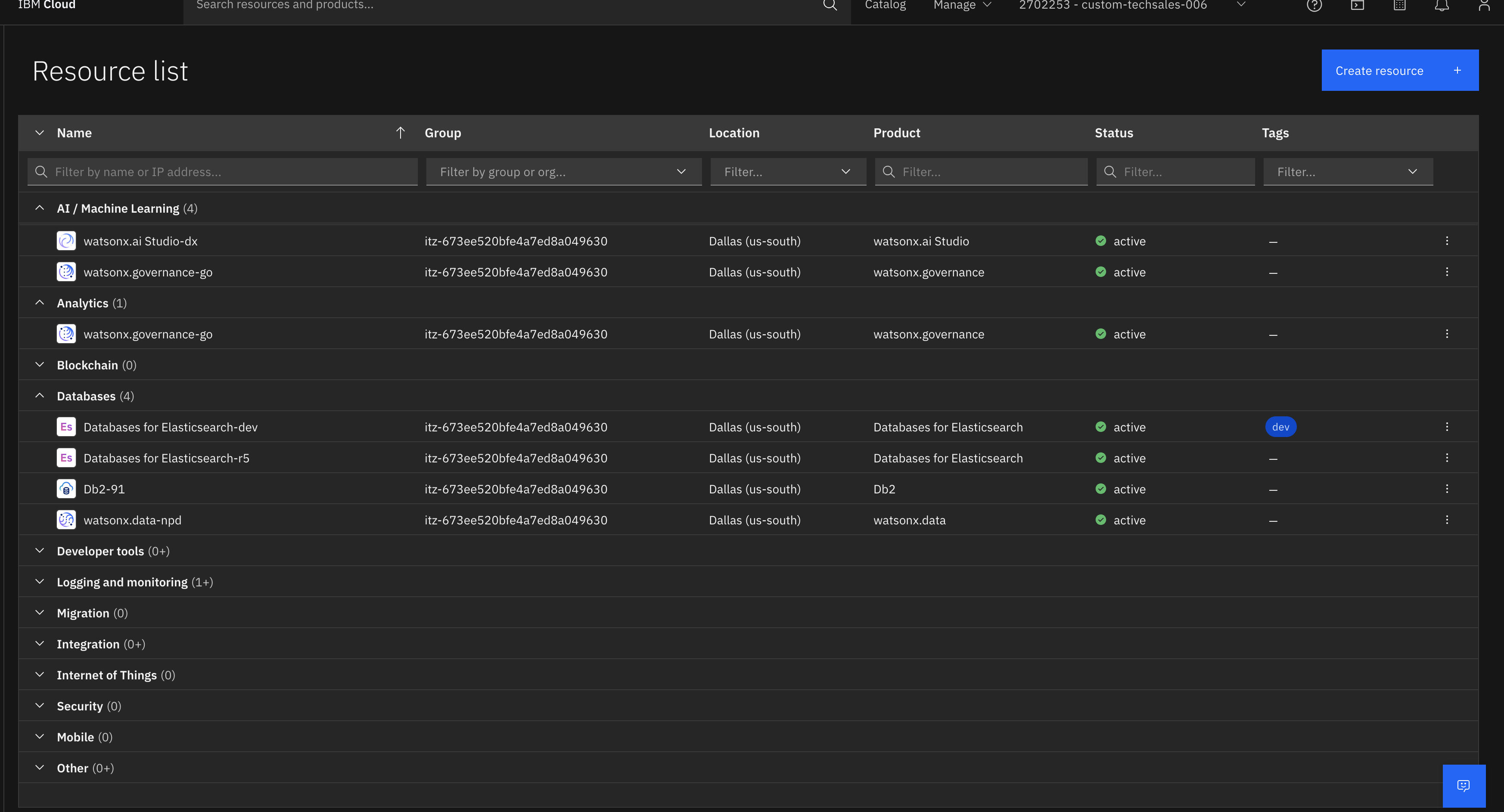
The setup leverages IBM Cloud services to ensure scalable and reliable performance. watsonx Orchestrate can be deployed as a service on AWS as well.
- AWS Marketplace:
watsonx Orchestrate on AWS Marketplace
AI and Automation tools
| Component | Purpose | Use |
|---|---|---|
| watonx Orchestrate | Workflow automation | Email distribution, PDF report generation, chat |
| watsonx Discovery | Data ingestion & search | Tax law updates, data exploration, RAG |
| watsonx.ai | AI model hosting and prompt testing | Report and email generation |
Data Processing Options
| Component | Use Case | Configuration |
|---|---|---|
| watsonx.discovery | JSON transformation, Elasticsearch | Configuration Guide |
| watsonx.data + Milvus | Vector storage, similarity search | Setup Guide |
| Custom Vector DB | Specialized indexing needs | Refer to specific database documentation |
Sample Elasticsearch Query
# Query financial data from ElasticSearch
response=$(curl -X GET "https://<your-elasticsearch-endpoint>/_search" \
-H 'Content-Type: application/json' \
-d '{
"query": {
"match": {
"document_type": "tax_regulation"
}
}
}')
echo $responseSample steps for watsonx.data integration-leverage latest IBM docs
# Example using watsonx.data with Milvus for vector storage
from pymilvus import connections, Collection
# Connect to Milvus
connections.connect(alias="default", host="localhost", port="19530")
# Define your collection schema (example schema)
from pymilvus import FieldSchema, CollectionSchema
import pymilvus
fields = [
FieldSchema(name="id", dtype=pymilvus.DataType.INT64, is_primary=True),
FieldSchema(name="embedding", dtype=pymilvus.DataType.FLOAT_VECTOR, dim=128)
]
collection_schema = CollectionSchema(fields, description="Collection for financial documents")
# Create the collection
collection = Collection(name="financial_documents", schema=collection_schema)
print("Collection created:", collection.name)IBM Documentation Links
- IBM Cloud Object Storage:
Cloud Object Storage Documentation - IBM Code Engine:
Code Engine Documentation - ElasticSearch on IBM Cloud:
ElasticSearch Documentation