Data Preprocessing
- Data containing tables needs to be pre-processed so that the LLM can properly read the content in tables.
- Before uploading to Watson Discovery, run the following script on your files if needed and upload the files generated by the output to Watson Discovery: link. Additional changes should be applied to this script in order to make it customized for your PDF documents. The provided script is for a specific set of documents that we used.
- The script interates through each page of the PDF file, finds all the tables, and transforms each table into natural language format utilizing LLM. Having tables in a natural language format will help with question and answering. The code will preprocess PDFs and output HTML files.
Create Project and Collection
- First launch Watson Discovery and then, create a new project
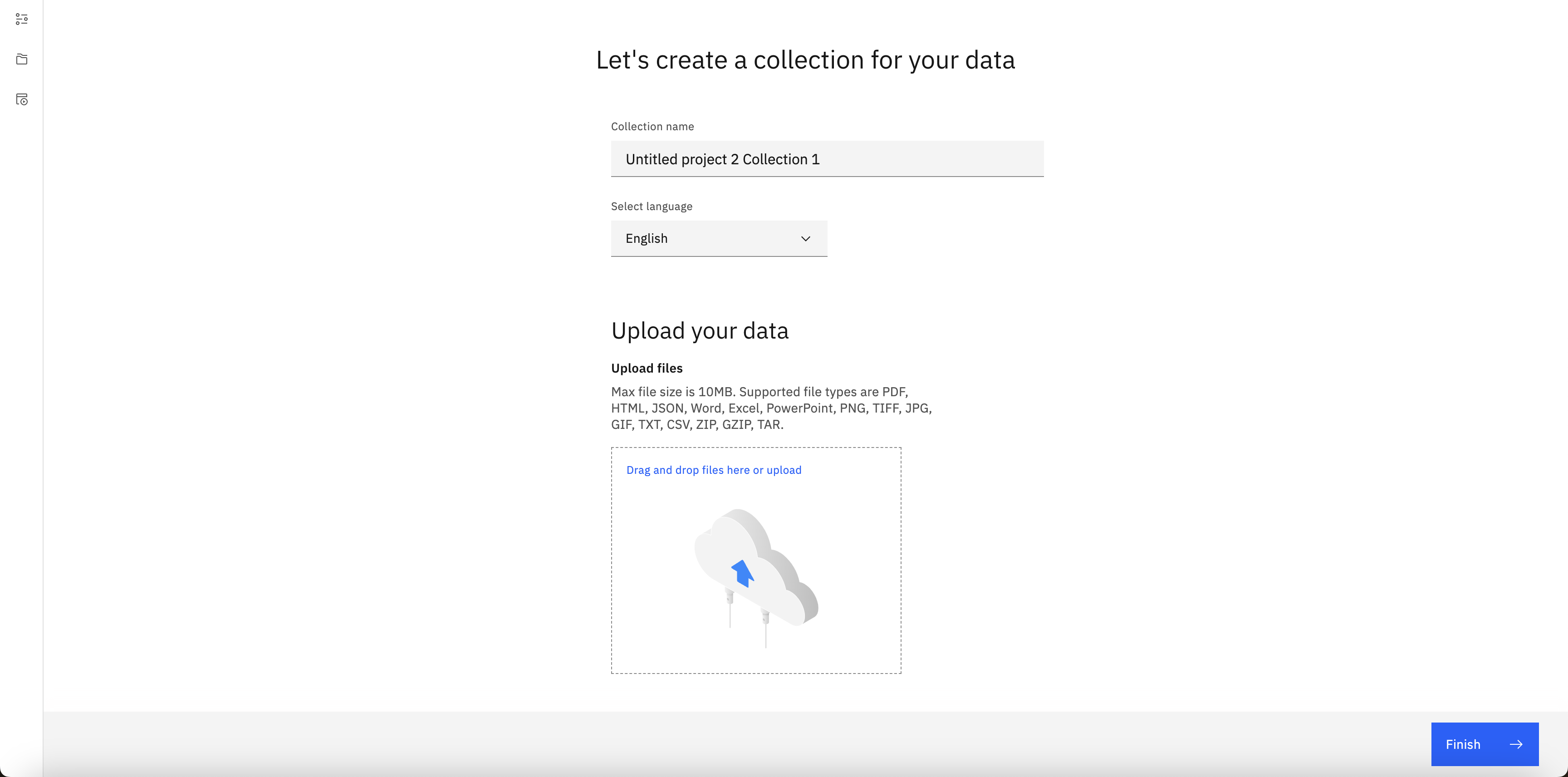
- Select Conversational Search as the Project Type and upload your documents into the drop down:
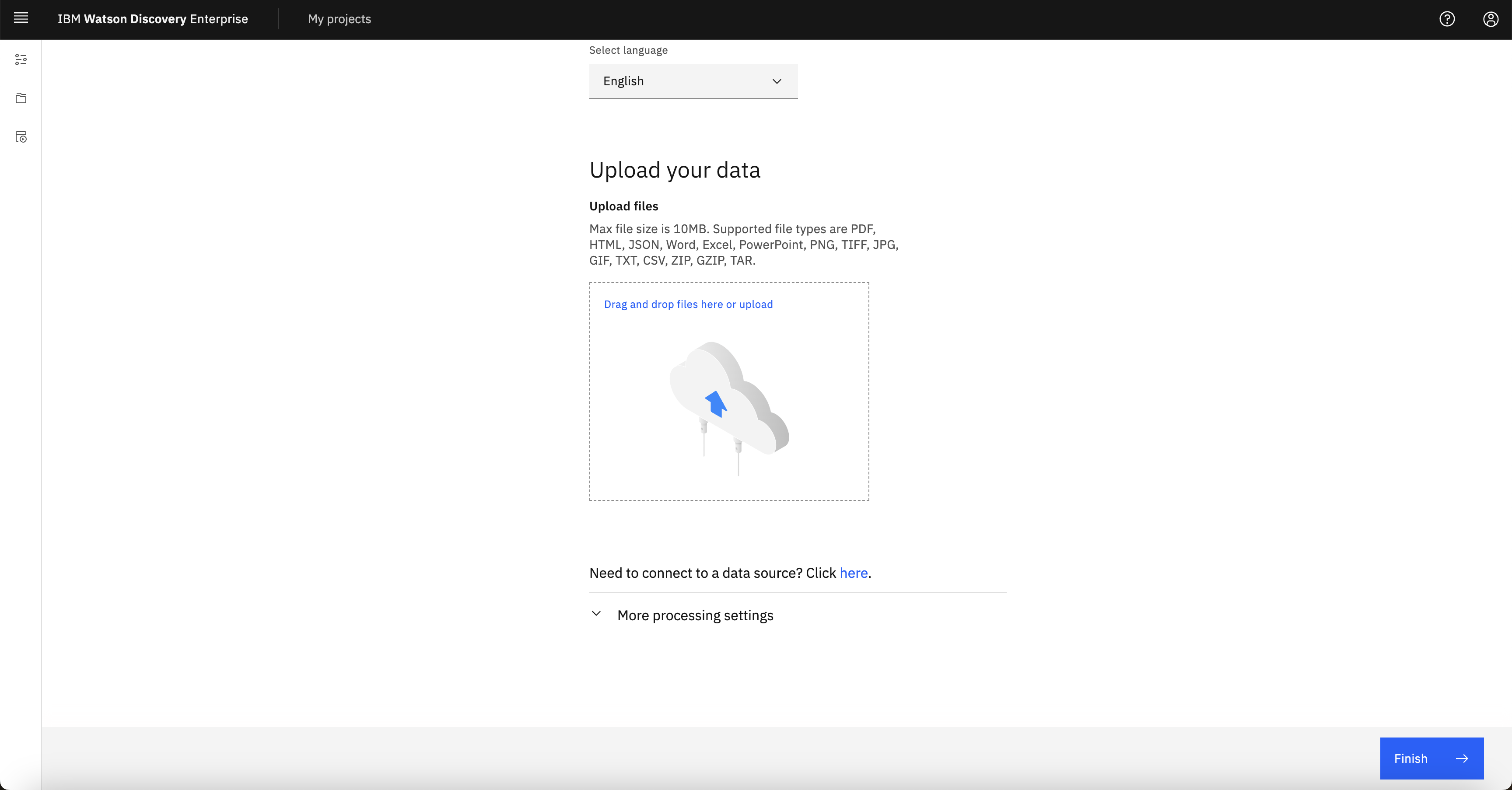
- If you will be web crawling your data, scroll down until you see the connect to data source option, click it and then select Web Crawl:
Upload documents
- Watson Discovery projects are organized by "collections" of documents. Documents can be queried at the project or individual collection level.
- Create the first project from a file upload and upload the knowledge base PDFs